Value vs. Reference Equality
The mutation of data in computer science is something everybody who has studied a common programming language has done at some point. You create a variable and they you change it! Magic! All of a sudden, you have a variable that is completely different, with a different value and everything! Well, actually, there's something that probably didn't change; the location of the data in memory. The variable is still pointing to the same place it always did; a little section it found specifically for the variable. The contents of the section had changed, but the reference - a sort of ID, if you would - is still the same. This is called mutating the value, and can therefore be seen as mutability.ReactJS's Spin
ReactJS has an interesting method of making rendering more efficient, and it involves the way you alter data. Instead of changing the values of a set object every time you need it to change (mutating it), you can actually adopt a standard that replaces the object with a new object altogether every time you intend to change it [2]. Such is the idea behind immutability.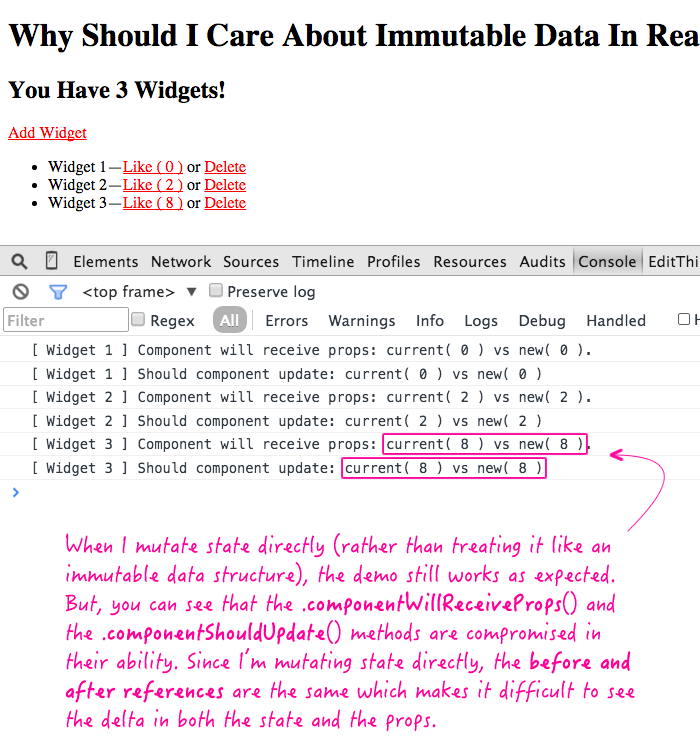 |
| Courtesy of BenNadel.com [10] |
Why would that make things any faster, though? Well, the way the parsing algorithm processes the alterations, replacing objects altogether secretly (or rather implicitly) gives these objects new reference locations. This allows the aforementioned diffing process to run with less consideration through the file (DOM); why even compare the values when you can just quickly see that the reference has changed. This may not seem quick to humans, but for an analyzer that can view the reference with less intensive processes, this is far superior[1, 2]. With this, the process of finding dirty data to update becomes less computationally intensive, noticeably so in large-scale or especially complex computations.
Comments
Post a Comment